The day began with a boaster session, during which all contributors had one minute to pitch their work. Some of these were particularly creative. Cathal Hoare, a PhD student at University College Cork, in Ireland, delivered his boaster as a poem. Sarah Gilbert of Dalhousie University, in Canada, used a Star Wars–themed odyssey to illustrate the challenges that Joe Student faces in writing a research paper. Vladimir Zelevinsky from Endeca let his animated slides speak for themselves—he remained silent for the entire minute. Despite the large number of boasters, the session was engaging and the time went by quickly.
Then came Dan Russell’s keynote, “Why is search sometimes easy and sometimes hard?”![]() Dan began by celebrating the successes of our current information retrieval systems. But he quickly dropped the other shoe: today’s systems still fail on a wide variety of tasks. Moreover, text-oriented search engines lag behind our input devices, which now commonly have cameras and microphones. But the bigger problem is that, while search engine developers have worked hard on improving the quality of data and algorithms, too little work has gone into improving the knowledge of users.
Dan began by celebrating the successes of our current information retrieval systems. But he quickly dropped the other shoe: today’s systems still fail on a wide variety of tasks. Moreover, text-oriented search engines lag behind our input devices, which now commonly have cameras and microphones. But the bigger problem is that, while search engine developers have worked hard on improving the quality of data and algorithms, too little work has gone into improving the knowledge of users.
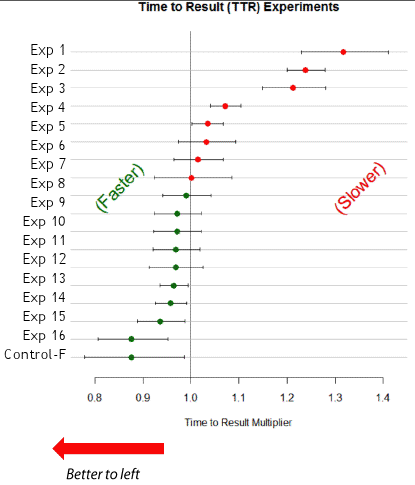
For example, 90% of users do not know they can find text in the content on a Web page using the keyboard shortcut Ctrl+F on a PC, Command-F on a Mac, or the equivalent command on the Edit menu. An experiment showed that teaching users to find text could increase their search effectiveness—as measured by the time it takes them to get to the desired result—by 12%, as Figure 1 shows. We are thrilled when an algorithmic improvement achieves a small fraction of that! In general, user expertise lags while search interfaces become richer and more powerful. While it was sobering to see how much users struggle with our current tools, it was encouraging to realize how much opportunity there is to improve user experience and effectiveness through support and education.
During the systems session, Klaus Berberich described a system supporting time-based exploration of news archives that researchers at Microsoft and the Max-Planck Institute for Informatics developed. It uses crowdsourcing to annotate timelines with major events. John Stasko spoke about an interactive visualization system researchers at Georgia Tech have developed to help users analyze relationships among entities. Both systems emphasize recall-intensive scenarios that we sometimes forget when focusing on precision-oriented Web search tasks.

