Quantitative Studies
Quantitative studies provide data that can be expressed in numbers—thus, their name. Because the data is in a numeric form, we can apply statistical tests in making statements about the data. These include descriptive statistics like the mean, median, and standard deviation, but can also include inferential statistics like t-tests, ANOVAs, or multiple regression correlations (MRC). Statistical analysis lets us derive important facts from research data, including preference trends, differences between groups, and demographics.
Multivariate statistics like the MRC or stepwise correlation regression break the data down even further and determine what factors—such as variances in preferences—we can attribute to differences between specific groups such as age groups. Quantitative studies often employ automated means of collecting data such as surveys, but we can also use other static methods—for example, examining preferences through two-alternative, forced-choice studies or examining error rates and time on task using competitive benchmarks.
Quantitative studies’ great strength is providing data that is descriptive—for example, allowing us to capture a snapshot of a user population—but we encounter difficulties when it comes to their interpretation. For example, Gallup polls commonly provide data about approval rates for the President of the United States, as shown in Figure 1, but don’t provide the crucial information that we would need to interpret that data.
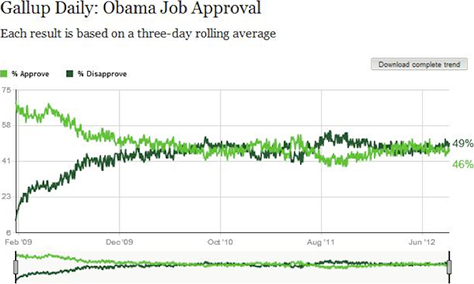
In the absence of the data that would be necessary to interpret these presidential job-approval numbers, it’s difficult to say why people approve or disapprove of the job that President Obama is doing. Some respondents may feel that President Obama is too liberal, while others may feel that he is too conservative in his actions, but without the necessary data, there is no way to tell.
In a product-development environment, this data deficiency can lead to critical errors in the design of a product. For example, a survey might report that the majority of users like 3D displays, which may lead to a product team’s choosing to integrate a 3D display into their product. However, if most users like only autostereoscopic 3D displays—that is, 3D displays that don’t require their wearing glasses—or like 3D displays only for watching sports or action movies on a television, using a 3D display that requires glasses for data visualization on a mobile device might not be a sound design direction.
Additionally, only someone with a firm grasp of how they should use and interpret quantitative statistics should conduct such a study. For most tests, there is an overreliance on the p-value and sample size. The p-value![]() is a statistic that indicates the likelihood that research findings were the result of chance. If a p-value is less than .05, the findings are said to be statistically significant—meaning there is less than a 5% chance that the results were the result of chance.
is a statistic that indicates the likelihood that research findings were the result of chance. If a p-value is less than .05, the findings are said to be statistically significant—meaning there is less than a 5% chance that the results were the result of chance.
It’s possible to manipulate a p-value by the sample size, but you need a sufficient sample size to have enough statistical power![]() to determine whether a finding is accurate. If your study is underpowered because of its having two small a sample size, you may fail to achieve statistical significance—even if the finding is accurate. On the other hand, if you achieve statistical significance with a small sample size, you don’t need to increase your sample size; the finding is true regardless. While the small sample size makes it more difficult to determine something, if you are able to determine something with a small sample size, it’s just as true as if you made the finding with a large sample size.
to determine whether a finding is accurate. If your study is underpowered because of its having two small a sample size, you may fail to achieve statistical significance—even if the finding is accurate. On the other hand, if you achieve statistical significance with a small sample size, you don’t need to increase your sample size; the finding is true regardless. While the small sample size makes it more difficult to determine something, if you are able to determine something with a small sample size, it’s just as true as if you made the finding with a large sample size.
By increasing the sample size, you can increase a finding’s statistical power, but perhaps to a point where the finding becomes less meaningful. There’s a common joke that a researcher can make any finding statistically significant simply by increasing the sample size. The reality is not too far off. However, it is possible to increase sample sizes to a point where statistical significance is barely meaningful. In such a situation, it is important to look at the effect size![]() —a statistic that tells you how strongly your variables effect the variance.
—a statistic that tells you how strongly your variables effect the variance.
Basically, statistical significance tells you whether your findings are real, while effect size tells you how much they matter. For example, if you were investigating whether adding a feature would increase a product’s value, you could have a statistically significant finding, but the magnitude of the increase in value might very small—say a few cents. In contrast, a meaningful effect size might result in an increase in value of $10 per unit. Typically, if you are able to achieve statistical significance with a smaller sample size, the effect size is fairly substantial. It is important to take both statistical significance and effect size into account when interpreting your data.

