IA Concepts
There are five concepts that drive the six steps for creating a Web site’s information architecture. The controlled vocabulary![]() of accepted terms from the DSIA Research Initiative includes these IA concepts:
of accepted terms from the DSIA Research Initiative includes these IA concepts:
- information architecture as work product
- context
- probes
- constructs
- IA common set
Information Architecture as Work Product
Let’s start with a definition. Information architecture is not just the name of a professional practice; it’s also the name that we give to our work product. The DSIA Research Initiative defines information architecture as “the assumptions and governing constructs for assigning properties and attributes to information and the endowment and evolution of information relationships over time within a given domain.” Put simply: “a governing model for information behavior.”
Not everyone may agree with this definition because of its narrowness. That’s completely fine. This is one reason that there are varying schools of thought![]() on the practice of information architecture for the Web.
on the practice of information architecture for the Web.
Ultimately, it’s not the definition that is most relevant; it’s whether the definition is actionable within the context of whatever you do. How a definition helps you—and the people or communities of practice with whom you work—to communicate and work effectively determines the value and utility of that definition. The definition that I use to define my information architecture work product has been pivotal to my success and has proven resilient in practice.
However you choose to define your information architecture work product—whether you create a new definition or adopt an existing one—you need to have a definition because it describes the thing you are creating to provide value to your design and development team and, ultimately, your business or client.
Context
While context is theoretically one of several major forces that influence the requirements for an information architecture, it is a factor that many people generally take for granted.
I’ve defined context as follows: “The temporally interrelated conditions in which something exists or occurs.” This is a slight modification of the Merriam-Webster definition. I’ve added the idea of temporality to the definition because the context of use for user interfaces is rarely static. Rather, context is usually a temporary event or state. But it’s this state that defines the scope and domain of an information architecture.
When we examine context, it helps to establish the subject domains that influence the mental models of our target users, dictate the language they use, and influence their dialogue, as well as a site’s content. These are all crucial inputs for designing an information architecture.
Because context is also about circumstances, a thorough examination of context typically involves the use of interrogatives: who? what? where? when? why? and how? It’s also useful to expand on these by asking how much? how often? and how long?
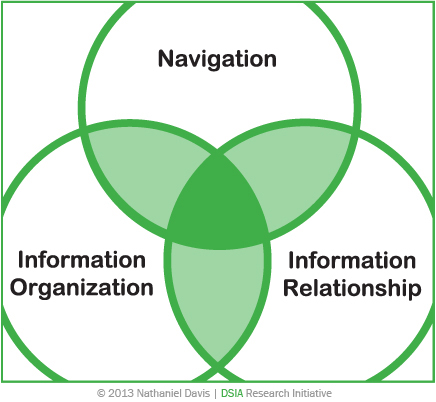
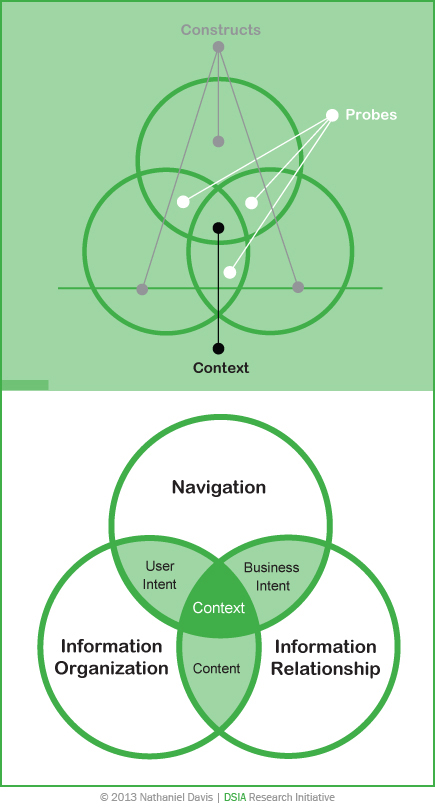
Finally, for an information architecture to be effective, it must expose and satisfy patterns of shared language, relationships between content, and user expectations. Exploring context aids this discovery, which is why context sits at the epicenter of our approach, as shown in Figure 1. However, while context is a central concern, it is not necessarily the first information that we acquire when we embark on a project. The more complex a domain—typically because of various contexts and audiences—the longer it can take to expose the contextual variables of a domain in full.

Probes
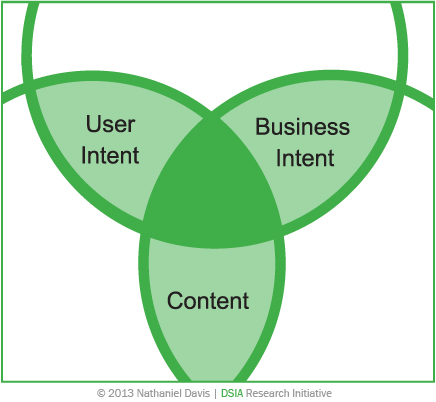
There are three primary probes that we use to develop the contextual assumptions that eventually influence the structure of an information architecture. When we view users’ engagement with a user interface as a communication exchange between a business and its target users—a typical scenario—our probes uncover and reflect the underlying intents of all participating parties and identify the more structured content objects that enable their communication, as shown in Figure 2.
In most situations, we probe for business intent and user intent. It’s possible for each to produce a segmentation comprising different personas and their respective contexts of use.
Probing user intent lets us record the key qualitative human factors that impact scenarios of information interaction and retrieval that are crucial to consuming content or using it in a flexible and unconstrained manner. Similarly, the act of probing business intent should uncover organizational needs, desires, and expectations through the people that model the business and execute its functions.
When probing business and user intents, we naturally incorporate a third probe: content. A Web site’s content supports the dialogue of any digital communication—from mundane transactions to recreational experiences—and is the capital that drives the information economy. Content includes images, graphics, text, audio, video, and raw data—in structured and unstructured formats. Any data that we can digitize can be content on a Web site. A core concern of information architecture in practice is understanding the essential nature and purpose of the content in any given domain to make it usable by assigning attributes and other properties to it.