The typical information architect thinks about structure—how one item in a group relates to all the other items in the group and how that group relates to all other groups. In the early days of information architecture (IA), groups and their related items tended to be well defined. For example, in the heyday of ecommerce, an information architect translated a product catalog into a storefront on the Web. Today, these problems seem old hat.
Modern Web technologies permit greater flexibility in navigation, search, retrieval, and display. At the same time, the quantity of information is growing exponentially, and users expect greater control over content:
more sophisticated interactions between browser and server—through the XMLHttpRequest object
more dynamic interfaces—through JavaScript and CSS
more flexible formats for distributing content—through XML and RSS
Champion Advertisement
Continue Reading…
Some practitioners are characterizing this technical evolution of the Web as Web 2.0.
Beyond the technology, however, Web 2.0 brings with it a shift in mindset. Today, people trust online content that individuals publish more than they did in the early days of the Web. Many people now willingly share information—like photographs or favorite Web sites or wish lists—freely on the Web and see sharing this information as beneficial.
The consequent explosion of content and functionality on the Web and the new ways in which we’re making use of Web content has recast the role of the information architect. This article explores the information architect’s evolving responsibilities in light of the changes we’re experiencing on the Web.
The More We Offer…
When people see potential in cool new features, they want more—even if they have to create it themselves. Empowered users feel a greater sense of ownership for online content—even if they didn’t create it—which translates to higher expectations for their ability to manage that information. One example of this phenomenon is the proliferation of RSS feeds. Like most of the technologies loosely forming Web 2.0, RSS has been around for a while, but it’s only in the last year or so that it’s gained traction.
RSS stands for Really Simple Syndication. RSS is a standard for formatting content with particular XML tags. A Web site publishes an RSS feed—an XML file that contains its latest content, in a format that follows W3C standards. Users subscribe to RSS feeds, which in turn notify them when a site has new content. In this case, subscribe means to check the feed periodically for anything new.
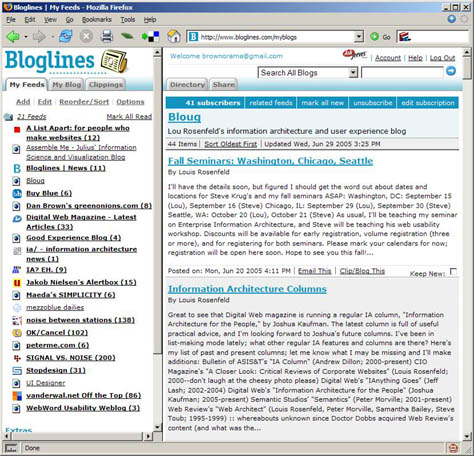
To subscribe to an RSS feed, you need a feed reader such as Bloglines, shown in Figure 1. Though some browsers have built-in feed readers, stand-alone feed readers are also available as both desktop and Web applications. They all offer the same basic functionality: managing subscriptions, indicating new content, and displaying content.
Figure 1—Bloglines, a widely used Web-based RSS feed reader
The hope was that RSS feeds would let users cut through the clutter and go right for the content that interests them. Since there are just about as many feeds as there are Web sites, however, this hope was quickly dashed. RSS feeds help users stay up to date on their favorite sites, but do little to stem the flow of content.
Imagine you’re an information architect who is designing a new feed reader. You’ll face the following questions—among others:
How should the feed reader facilitate finding new RSS feeds? Will the feed reader recommend additional feeds based on the current subscriptions?
Should the feed reader filter the feeds, displaying new content from predefined categories?
How much content does the feed reader need to display to help facilitate decisions about what to read?
How should the feed reader store feeds?
Although you, as the information architect, are not working on strict taxonomies, you are considering essential IA problems—structuring information in an accessible way. While the structured, linear format of an RSS feed gives you some foundation, the feeds themselves are constantly and unpredictably changing as sites add new content. This means you are working with a corpus of data that’s constantly in flux.
The More They Want…
Sophisticated users, who have specific ideas about how to manage their information, present one set of challenges to the next generation of information architects. The ballooning amount of information offers a different set of challenges. More and more sites permit people to publish their own content, and individual publishing is a major source of the increase in the volume of online content.
While Weblogs may be the most obvious example of individual publishing, there are other online applications that have also contributed to this explosion. There are now Web services for managing information that people previously stored locally, on their own computers—events, bookmarks, photos, and contacts, among others. All of these Web services allow users to carve out virtual space for storing their information rather than hard disk space. One online application that serves this purpose is the wiki.
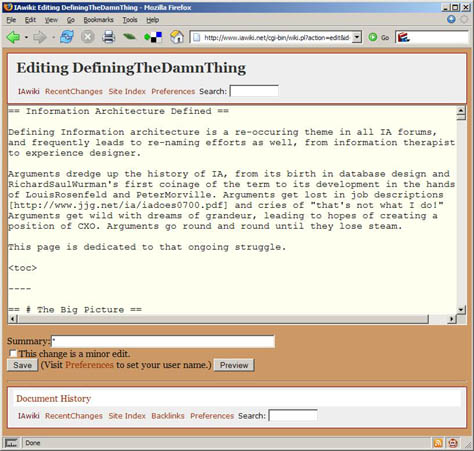
Wiki software is gradually gaining popularity as companies like WikiMedia, 37signals, and JotSpot find ways of improving upon the basic premise of a wiki to make them more accessible and useful. Like most new Web technologies, wikis are services that have no obvious real world analogue. The simplest description of a wiki is a set of Web pages that anyone can edit—though this definition loses some of the magic of wikis. Wikis provide simple editing tools such as those shown in Figure 2—allowing people to log in and create content. Although quite different from blogs, wikis lower the barrier to entry for Web publishing in much the same way that blogs do.
Figure 2—Editing a page on IAWiki.net
Wikis may present the information architect’s ultimate challenge: a virtual information space with no structure, to which anyone can contribute. Generally, the more successful wikis and collaboration spaces have some overriding structure and follow certain standards. Consider Wikipedia, perhaps the most well-known wiki. Wikipedia is an online encyclopedia whose authors and editors are volunteers from the online community. Yet, like a real encyclopedia, Wikipedia has strict content standards—what’s acceptable and what’s not—that their community enforces.
I don’t know if Wikipedia has an information architect. My guess is that they do not, given the underlying philosophy of the site. Still, Wikipedia illustrates the kinds of information architecture problems we face today. Even if there’s no one on their staff who calls herself an information architect, there are people in the community filling this role. This may suggest that there’s no value to having an information architect on staff, if community volunteers can easily fill the role. This model may work for Wikipedia, but businesses using wiki software may not have the luxury of waiting for content and categorization standards to emerge from the community or having those standards enforced ad hoc.
Digging a little deeper into Wikipedia, it’s possible to see standards emerging across similar entries. For example, take Wikipedia’s entries for Wesleyan University, my alma mater, shown in Figure 3, and Duke University, my wife’s alma mater. Both entries have sections on “History” and “Academics.” Both have sections on famous alumni—though Duke’s is called “Famous and Distinguished Alumni,” while Wesleyan’s is simply “Notable Alumni.”
Figure 3—Wesleyan’s entry on Wikipedia
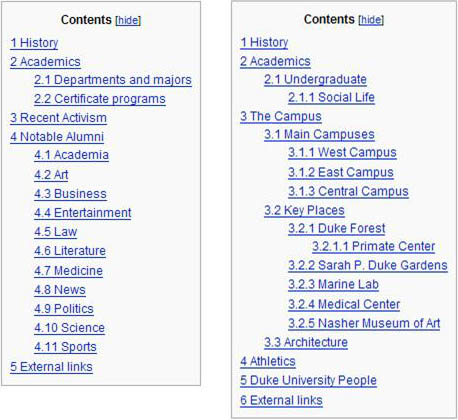
The structures of these entries include elements that make them distinct, too. Duke has a section on “Athletics,” which is conspicuously absent from Wesleyan’s entry. On the other hand, Wesleyan’s entry includes a section on “Recent Activism,” but Duke’s does not. Figure 4 provides a side-by-side comparison of the tables of contents for the Duke and Wesleyan entries on Wikipedia.
Figure 4—Contents for Wikipedia’s Duke and Wesleyan entries
Although Wikipedia has a taxonomy of subjects, the primary information retrieval mechanism appears to be search. The categories themselves are somewhat ad hoc and non-exclusive. For example, one of Duke’s categories is “Universities and Colleges in North Carolina.” Despite the apparent arbitrariness of the categories, the category pages seem to follow a particular standard, just as the individual entry pages do.
The point here is that establishing and using a standard structure enhances the value of community-contributed content. Flexibility in the standard structure of entries is necessary in order to highlight potential distinctions between otherwise similar entries—as in the case of “Athletics” or “Recent Activism”—and to allow the emergence of obscure categories—for example, “Universities and Colleges in North Carolina.” At the same time, the standard structure must be clear and easy to follow.
The traditional role of an information architect focuses on devising useful categories of content. Within a dynamic space like Wikipedia, an information architect would
guide and coax contributors to create content using standard formats
create a framework for eliciting and capturing content
create a framework for displaying categories of content, but not necessarily the categories themselves
Wikis are Petri dishes for content and, since anyone can contribute content, they carry the risk of serious contamination. With a scope as big as Wikipedia’s, devising a standard structure for the site may seem like an impossible task for an information architect, and it is. But Web 2.0 calls for something else entirely: a more abstract scope. For Web 2.0, information architects must focus on the higher-level structures that create an overall information framework for a site.
The Less We Have To Work With
Individual publishing is only the beginning. The Web 2.0 paradigm shift has also introduced new sources of metadata. Typically the domain of specialists, metadata is information about information. Metadata supports various tasks like retrieval, administration, access, and more. Although allowing the consumers of information to contribute metadata is hardly a new idea, there are new implementations popping up online. Most notably, free tagging.
With free tagging, users have the opportunity to apply labels, or tags, to content in an unstructured way. Users are free to enter whatever labels they feel are appropriate. This approach is distinct from more traditional metadata approaches in at least two ways:
The words used for tags do not come from an authoritative source like a controlled vocabulary.
The tags can apply to any kind of data and do not relate to specific fields like author, topic, or source.
Free tagging is controversial. Some think it renders librarians and information architects obsolete, because there is no longer a need for formal categorization. At the other extreme, some insist that the metadata people create by free tagging is of no value. The moderate view is simply that free tagging and formal classification are two different techniques that address different problems.
Two typical examples of free tagging are del.icio.us, which allows people to assign tags to bookmarks, and Flickr, which allows people to tag photographs. The main uses of tags in these applications are to allow users to
find previously viewed or contributed content again
navigate the sites serendipitously
By tagging my bookmarks on del.icio.us with keywords that are meaningful to me, I can easily find them again. This saves me from having to remember how I found the resource in the first place—whether through search or navigation categories. Free tagging allows me to create bookmarks within the context of my work and my life.
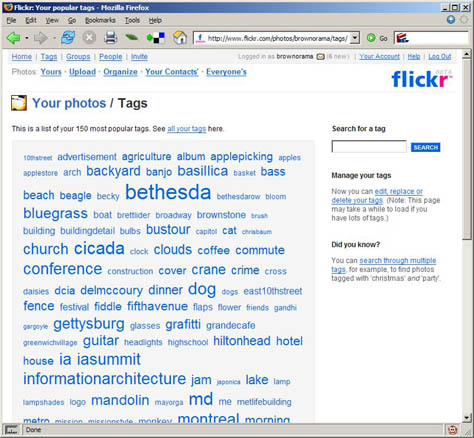
Flickr provides good examples of serendipitous navigation. I’ve used keywords to tag my photographs on Flickr, as shown in Figure 5. By clicking a keyword, I can see photographs that other people have tagged using the same label. In this scenario, users are not necessarily interested in seeing every possible entry in the library of photos. The loose network of keywords on Flickr makes it easy for users to take a virtual journey, tripping over treasures, and enjoying the Web’s scenic view. Thomas Vander Wal coined the term folksonomy for this network of keywords.
Figure 5—Keywords I used to tag my photographs on Flickr
While opinions on this approach vary wildly, free tagging does offer one important advantage in a Web environment where more and more content is community contributed. Users do not have to exert much mental energy to determine appropriate keywords for specific entries. When given a choice, users will shun creating metadata when there are too many constraints on what is permissible. Free tagging effectively removes the constraints of controlled vocabularies and metadata categories, lowering the barriers to entry for capturing useful information.
Herein lies the challenge to the information architect. Traditionally, metadata adds structure to otherwise unstructured content. Modern systems open the possibility of unstructured metadata and, in this context, information architects must
determine whether their projects would benefit from lower barriers to metadata creation
weigh the benefits of lower barriers against the potential costs of unstructured metadata
design systems that effectively leverage unstructured metadata, imposing structure where there is no implicit structure
Conclusions
Three factors are creating new challenges for information architects that have emerged with Web 2.0:
users expecting more control over information management
large and dynamic information spaces
unstructured metadata
What all three factors have in common is that they force information architects to think about underlying structures. Rather than developing concrete navigation categories or prioritizing certain content over other content, an information architect must think more abstractly. The domain of today’s information architect includes not only organizing information into categories, but principles of organization as well. Gone are the days when information architects could do a card sort alone to establish an information structure for a Web site.
The complexity of modern Web services demands the same level of rigor in their information architectures while, at the same time, requiring that we design information spaces on a more abstract level. With users continually contributing both content and metadata, information architects have much less raw data to work with up front. Instead, they must think about the structures and patterns that govern these dynamic information spaces without losing sight of their primary responsibility: ensuring people can find the information they need.
Author acknowledgement—Special thanks to James Melzer for providing a critical peer review on an early draft of this article.
Wow. This article covers quite a bit of ground. I too believe that a “modern” Information Architect must take into consideration new approaches to organisation. However, I am a bit concerned that many people are swinging too far in the other direction, eschewing any sort of proper sorting or hierarchy. I wrote a bit about this on my weblog here.
Actually, I would have made this a trackback, but I didn’t see that as an option.
Oh, and congrats on the new magazine. I’ll be adding the feed to my newsreader!
Great IA article!
Are you aware of any TrackBack-esque options that would help facilitate permalink connectivity and thereby help us all to ramp up the ability to communicate en masse more effectively?
I’m a student from Universiti Teknologi Malaysia, Malaysia. Maybe, in December 2007, I will be continuing my study in Masters of Information Architecture. Firstly, I’m new in information architecture. I really want to know about the new techniques and tools that can be used in information architecture. Thanks for your cooperation.
You should have given Ohio Wesleyan University’s entry on Wikipedia as an example. It is a featured article on Wikipedia and is way better than the Wikipedia entry of 99% of other colleges or any other Wesleyan, including Connecticut Wesleyan.
I’m very glad to read your article. I want to know whether there are more articles about Information Architecture 2.0 that you have published. I want to communicate with you about this issue sincerely.
Dan has practiced information architecture and user experience design since 1994. Through his consulting work in both the public and private sectors, Dan has improved enterprise communications for both Federal and Fortune 500 clients, including The Federal Communications Commission, The Postal Service, US Airways, Fannie Mae, First USA, British Telecom, Special Olympics, AOL, and the World Bank. Dan has taught classes at Duke, Georgetown, and American Universities. He is a popular speaker and writer on topics relating to information architecture. Most recently, Dan taught a pre-conference tutorial at the 2005 IA Summit on using Microsoft Visio. He is very active in the local Washington, DC, information architecture community and organizes regular workshops there. In 2002, Dan collaborated with information architects around the world to establish the Information Architecture Institute, the first professional organization dedicated to the craft. Read More