Types of Patterns
There are a number of different types of patterns that can provide useful insights, including
- trends—A trend is the gradual, general progression of data up or down.
- repetitions—A repetition is a series of values that repeat themselves.
- cycles—A cycle is a regularly recurring series of data.
- feedback systems—A feedback system is a cycle that gets progressively bigger or smaller because of some influence.
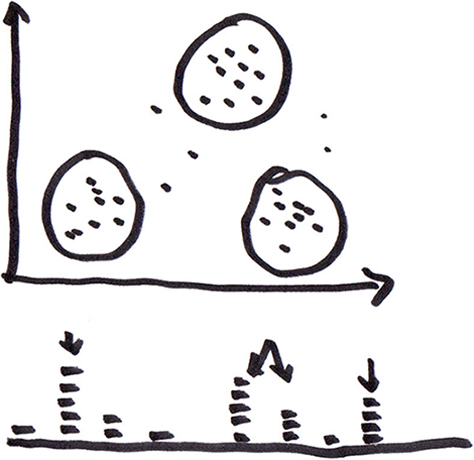
- clusters—A cluster is a concentration of data or objects in one small area.
- gaps—A gap is an area in which there is an absence of data.
- pathways—A pathway is a sequential pattern of data.
- exponential growth—In exponential growth, there is a rapidly increasing rate of growth.
- diminishing returns—When there are diminishing returns, there is a gradually decreasing rate of growth.
- long tails—The Long Tail is a pattern that rises steeply at the start, falls sharply, then levels off over a large range of low values.
Let’s look at each of these types of patterns in more detail.
Trends
When data shows a clear trend, all data progresses in the same direction. In an upward trend, each subsequent piece of data is higher than the last, In a downward trend, each subsequent piece of data is lower than the last. Trends can show up in various types of data such as site visits, subscriptions, and transactions.
In a trend, the progression of data up or down is almost never completely smooth. Every now and again, the data will dip down or shoot up, against the general trend. If you plot the data as a graph, the line will look jagged and rough.
Recognizing trends is often a matter of looking at the data at the appropriate level of scale. If we look at data too closely, all we see is a series of peaks and troughs, lacking any real sense of a direction. However, when we zoom out and view a greater range of data at a time, the overall shape of the data becomes much clearer.
Identifying trends—particularly when viewing data you’ve collected over a long period of time—can be difficult if the length of time each data point represents is short. Because the data constantly shifts up and down, an upward trend can appear to be heading downward or vice versa. For example, we see this in debates about global warming. If you look at just the last few years’ data, it’s difficult to identify a trend. If anything, temperatures appear to be dropping. Over the past 100 years, however, the upward trend is clear.
Repetitions
Often, in data, we’ll see a series of numbers or values repeating themselves. In a repetition, one value might consistently follow another or, when a value occurs, it might repeat three or four times before shifting to another value. Repetitions are slightly, but significantly different from cycles, which I’ll discuss next, in that the entire sequence does not recur.
Repetitions can indicate either that a process is stuck or that there’s some kind of relationship between one event and another—a causal relationship perhaps. For example, a longer task completion time might be followed consistently by very short times that result from task abandonment.
Cycles
Cycles like those shown in Figure 1 are easily recognizable, because each segment of the data looks similar. In a cycle, there is a regularly recurring pulse or beat that is reminiscent of the beat of a heart or the ebb and flow of the tides.

Cycles indicate some underlying rhythm to an event you’re observing and measuring. Examples might include the rise and fall of Web site traffic during a day, the Christmas peak at an online store, the subsequent peak in eBay sales just after Christmas, or an increase in online gaming time during each summer break.
Recognizing the presence of a cycle and understanding the driving forces behind it can help you plan ahead and gain deeper insights into your audience.
Cycles can also alert you to the presence of negative forces, acting against growth. For example, advertising campaigns drive sales, which can increase the load on a poorly designed logistics and customer service system, resulting in unhappy customers who spread the word about their poor experience, thereby reducing demand on the logistics and customer service teams. The net result is that the volume of sales rises, then drops.
Feedback Systems
As depicted in Figure 2, feedback systems are like cycles that get bigger and bigger—or smaller and smaller—because some influence gives the system a small kick each time around. For example, sites that perform well during busy, seasonal periods such as Christmas or Thanksgiving, because they deliver good service and provide a good experience, might still see sales drop off during the rest of the year—only to see them peak at even higher levels during the same periods in the following year.
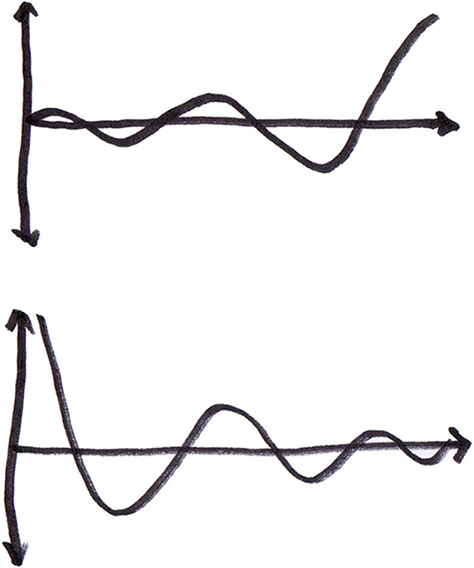
Feedback patterns can also indicate that a process is out of control. Variations become more and more accentuated as one event exacerbates the next. The infrastructure issues Twitter experienced in the early part of 2008 could serve as an example. Small improvements in capacity led to greatly increased traffic, resulting in the system’s becoming overwhelmed once more.