There is an adage in software development that says there are only three types of documentation that have ultimate value:
code
user assistance
test cases
This adage does not mean that other documents such as functional requirements, documentation plans, wireframes, personas, and such do not have value. It merely means that you do not want to be a year, a thousand pages, or a million dollars into a project and not have any code, user assistance, or test cases.
Most iterative design frameworks such as the Rational Unified Process (RUP) or agile software development embrace the principle of getting to demonstrable, testable code as soon as possible. Typically, they achieve this by separating the product requirements into functional chunks, then systematically developing each of those chunks through sequenced project phases that are sometimes called iterations. The early iterations usually comprise architecturally significant or technologically risky functionality.
Champion Advertisement
Continue Reading…
This article presents an approach to Help file design that focuses on creating a task-centered user experience and accommodates an iterative development strategy. This methodology allows the introduction of user assistance into early test phases—not only getting earlier validation for its accuracy, but also supporting quality assurance testing by serving as the test scripts for interactions with the user interface. This approach can also be a self-contained strategy—that is, one that allows an iterative approach to user assistance development even if the rest of product development operates on a waterfall model.
Selecting an Architectural Focal Point
Optimizing a user experience of any sort means understanding where the experience starts, then accommodating user needs at that time and place. For example, when designing a restaurant, an architect envisions an attractive main entrance and makes that the focal point for starting a satisfying user experience—one that guides people gracefully through the transition from a busy street to a cozy dining room. You can take a similar approach to designing a Help system by first envisioning how the user will access Help.
In general, there are five ways a user can get to a Help topic:
navigating through the Help table of contents
searching for a Help topic, then clicking a link in the search results
clicking a link in an index
clicking a link in another Help topic
clicking a context-sensitive link in the application’s user interface
Following a task-centered design approach makes it apparent that the primary entry points to a Help system should be context-sensitive links in the user interface. Create an architecture that optimizes this user experience. There are several reasons for making such links the focal points of a Help system.
One of the primary objectives of user assistance is to provide support to a user while the user is performing a task with an application. Most users try to do a task before consulting user assistance—usually they wait until they get stuck before resorting to Help. Therefore, users are typically within an application and already in the middle of a task when they consult Help. A context-sensitive link offers the best opportunity to serve users quickly and efficiently at their point of need. You can focus the entry topic on the information users most likely need—essentially making the user assistance experience a one-click transaction.
Another reason for focusing on context-sensitive entry points is that it lets you more easily link Help instructions to the product’s functional user interface. As I discuss later in this article, this close association between Help topics and the user interface accommodates an iterative development strategy that supports the early documentation needs of quality assurance and allows early testing of critical user-interface-to-Help links.
Defining User Assistance Iterations
You can define user assistance iterations along two dimensions:
product functionality
degree of completeness
These two dimensions are by no means mutually exclusive. For example, if you are supporting a product being developed using an iterative methodology, you can focus on developing user assistance topics that support an iteration’s targeted functionality. But you could also define the degree of completeness you intend to achieve along the product’s development and test cycle. As user assistance designers and developers, we do not have much control over the first dimension—the functionality in an iteration. However, we do have a lot of control over the second dimension, the degree of completeness we will deliver at any given time.
As I said earlier, this iterative model of user assistance development does not require an iterative model at the product development level. The most inflexible of development models, the waterfall―in which a project lumbers through whole product-sized clumps during the planning, design, development, and test phases―has time-phased testing and release milestones that let Help developers employ degree-of-completion iterations. Even the most simplistic model has two critical milestones:
Release to Quality Assurance (QA)
Release for General Availability (GA)
In most cases, a product’s test schedule is more granular and also includes alpha testing—when developers pound on functional versions of the code before releasing it to QA—and beta testing—when a company releases a product to select customers, who have reduced expectations about the completeness and performance of the product.
In a project I am currently working on, the project plan for the product identifies three critical milestone dates:
Delivery to QA
Delivery to Beta
General Availability
Obviously, the Help must be robust and complete by the General Availability date, but this project plan gives us two opportunities for releasing less-than-complete versions of the Help—the first to QA on that milestone date; the second to Beta.
Designing Help
When products have page-level or tab-level context sensitivity, the design process I am about to describe can very efficiently support iterative releases of testable code. We are using an open standard methodology called DITA (Darwin Information Typing Architecture) with an open source topic-mapping tool called Task Modeler. The DITA capability of semantically typing topics as Task, Concept, or Reference facilitates the approach I describe in this article, and the DITA mapping view within Task Modeler facilitates the design and file-stubbing steps I describe. However, applying this approach requires neither DITA nor Task Modeler.
The following overview summarizes the process for an iterative approach to creating Help:
Identify the pages that need context-sensitive Help. If the product has embedded Help, treat that as context-sensitive Help. You’ve merely removed the need for a user to click an icon or link.
For each of the pages the Help system supports, define a task-support cluster of Help topics. (I am about to discuss what that is.)
Stub the file structure—creating files that have topic titles and the required inter-topic navigation links, but not necessarily any of the content.
Write the task topics first.
Flesh out the clusters with the conceptual and reference topics.
Identify and write background and overview topics.
Task-Support Clusters
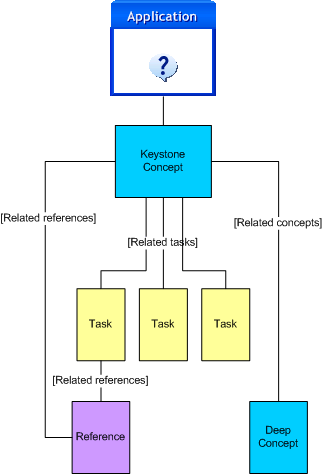
A task-support cluster is a closely associated group of Help topics you design specifically to meet the requirements of a user who is currently engaged in a task using the user interface. Its opening topic is called the keystone concept, and it is either a topic a user displays by clicking a context-sensitive Help link or the default topic in the embedded Help pane for a specific page. In designing the task-support cluster, make these assumptions:
A user has the necessary computer and domain knowledge to be doing the task—although the user might lack the full knowledge or experience an expert would have. I call this assumption the “you must be this tall to ride this ride” principle.
A user is in the right place to perform the task the user wants to do.
These assumptions will not be 100% true 100% of the time, but you are designing the primary user assistance experience at this point, not the complete user assistance experience. You can provide mitigation strategies for those users who do not fulfill these assumptions later. However, making these two assumptions lets you choose topics and write content that get the average user out of the Help and back on task within the application as quickly as possible.
A task-support cluster has the following elements:
an introductory keystone concept topic—which is the target of a context-sensitive link in the user interface and provides a functional overview—what you can do on this page. It can also augment domain expertise by providing tips or examples that give insight into how best to use that page to accomplish user goals.
task topics—which support the possible user goals for functions on the page
any reference topics—which users might require in support of those tasks
deep concepts—which, if appropriate, are more detailed than the keystone concept and present either more elementary information—for example, if the targeted task uses wildcards, how wildcard rules work—or more technical information—for example, if a targeted task initiates system activity that might be of interest to an advanced user who is trying to anticipate impact on network performance, how the system processes network traffic in the background. Either of these types of topics might be unnecessary clutter to the average user, but less-experienced or more-experienced users could find them valuable. However, deep concepts should still be closely related to the tasks a page supports.
appropriate inter-topic links—which are links to other topics within the cluster
Figure 1 shows an example of a typical architecture for a task-support cluster.
Figure 1—Architecture for a task-support cluster
Guidelines for Designing Task-Support Clusters
Here are some guidelines for designing task-support clusters:
Do not provide extraneous links—links that do not apply to the targeted task. Avoid the temptation to link the Help topics from one task-support cluster to another. For example, a page for selecting recipients to receive alert notifications by email is only loosely related to another page for configuring email. Assume a user’s targeted task is to set up notifications, not configure email, and quickly get the user back to the user interface to finish that task. Certainly, you can point out dependencies and tell the user how to get to dependent pages, but let the topic-support clusters for those pages pick up the burden should the user need help there.
Include navigation instructions in all task topics, either as explicit steps in the procedures or as links to navigation tasks. This mitigation accommodates users who get to Help topics through the Help table of contents, index, or search.
Be parsimonious with content and navigation. Your primary goal is to get the user back on task as quickly as possible.
But what if a page is very simple and creating a task-support cluster would be overkill? Then don’t do it. If a single task topic with a well-written goal or context statement can support a user goal, just create that. Or if Help cannot add any information beyond what the text in the user interface already provides, don’t add a context-sensitive Help link to that application page.
On the other hand, what if the task touches on broad areas of domain expertise that some users may lack―failing the “you must be this tall to ride this ride” criterion? Include educational topics in the larger Help file—such as tutorials and overviews like “Principles of Network Security.” Just do not include links to such extraneous information in the task-support cluster—or include just a single link to the top-level topic. The point is to avoid the inevitable link farm that results if you try to provide links to all conceptually related topics. Such over-linking makes a Help system unnecessarily complex and encourages users to read about functionality when they would be better off back in the user interface actually doing something.
Defining Iterations
Let’s review the process for this iterative approach to Help:
Identify the pages that need context-sensitive Help.
For each of the pages the Help system supports, define a task-support cluster of Help topics.
Stub the file structure.
Write the task topics first.
Flesh out the clusters with the conceptual and reference topics.
Identify and write background and overview topics.
Your first iteration of the Help for early quality assurance (QA) testing might deliver just the user assistance structure you create in steps 1 through 3. As I mentioned earlier, because my company uses a topic mapping tool, Task Modeler, it is very easy for us to graphically design the structure of our task-support clusters and create stubbed XML files. Our DITA editor can easily transform those XML files into a Help file with navigation. So, with just our architectural design work and very little information development work, we can deliver a skeletal file to QA, who can then validate the navigational integrity between the user interface and the Help as well as among Help topics.
However, you would probably want your initial iteration of Help to be more complete and perhaps include the content for the task topics as well. That would allow QA to use the Help topics as test scripts—that is, QA can follow the documented procedures in the Help tasks and verify that the user interface behaves as described. A good first iteration, therefore, is one that includes steps 1 through 4.
Later iterations of the Help can flesh out the keystone concepts, references, and deep concepts within the task-support clusters. Subject-matter experts can review the content of these topics independently, because there is no need to verify them against the working user interface, as reviewers must do with tasks.
Even later iterations of the Help can develop basic conceptual topics such as overviews, broad background topics, and general support topics that you create to help users who come to the application “not tall enough to ride the ride.” Instead of supporting specific tasks—read to do—such topics are more educational in scope—read to learn. You can also develop advanced conceptual and reference topics in these later iterations to support advanced users.
As you can see, you can shape an iteration strategy around the functionality dimension—for example, “The Help we deliver on such-and-such a date will cover functions A through F,” as well as along a degree of completeness dimension, “...and cover just the task-support clusters, with only the task topics fleshed out.”
A typical iterative strategy could look like this:
Milestone
User Assistance Iteration
Code to QA
Task-support clusters stubbed, with task topics completed
Beta
Task-support clusters fully developed
General Availability
Overviews and educational topics completed
You can describe this iterative approach to design and development using an anatomical metaphor. Your first iteration is a neuro-skeletal build. You are laying out the framework and interconnections—hypertext links. The next iterations are the muscular builds. You are fleshing out the core-value topics that do the heavy lifting of the user assistance. Later iterations are the organic builds—adding the skin and final components that make it a fully viable entity.
Benefits of an Iterative Approach
The benefits of the approach I have described in this article are two-fold. This approach encourages the development of user assistance that is more relevant to users’ needs. Furthermore, it provides a development approach that lets user assistance authors connect with the product development and testing lifecycle sooner. In summary:
The task-support cluster approach creates a strong user-centered, task-focused user assistance architecture. In effect, each cluster serves as an information express lane for users who have specific information requirements that their immediate tasks shape.
The modularity and self-containment of the clusters help prevent users from getting lost in the Help. Many user assistance authors over-link their topics. Thinking about Help navigation in terms like “Oh, if a user is reading about x, she would probably also be interested in y,” gets replaced with this: “The user who came here was doing x; let’s deal with that and get her back into the application, not other topics in the Help.”
The linking of the clusters to specific application pages and the emphasis on initial development of task topics allow early releases of Help files that can have immediate value in QA testing.
Very thorough and helpful article. The concept of not linking support clusters sounded counterintuitive at first. But I see how it would allow most users to focus on the core task and return to the right path.
Exactly! The keystone concept could include who gets alert notifications and when they might be helpful. The deep concept might be interesting to someone more technical like a system admin who needs to know how traffic flows on the system, but not something the typical user would want to know.
Thanks for adding value to the discussion with such an accurate concrete example.
This is a nice article. I like it very much, but I have a question about Help files and documentation: How many kinds of Help files are there? What is the most popular use? Advantages and disadvantages of these Help files and other documentation? Thank you in advance.
Big question. :-) First of all, a Help file is user documentation bundled for software or Web applications, bundled as part of the application, and accessible from within the application.
The Technical Answer: Some Help systems are proprietary and coded as part of the application code—for example, putting the Help text into Java properties files and using the application code to display the Help.
Other Help systems are written using Help Authoring Tools (HATs) such as RoboHelp or MadCap and exist as code outside the application, but with links or calls from within the application code that open the Help. These systems are often context sensitive—that is, they call up the appropriate Help topic based on where in the application the call comes from. Of these systems, the most common forms are HTML Help, which is a Microsoft standard that uses browser technology, but produces the Help file as a single compiled file—with the extension .chm—and Web-based Help, which creates each topic as a stand-alone HTML page and then renders the Help in a frameset that includes Contents, Index, and Search. There is also an emerging standard that uses the IBM Eclipse-based Help that takes advantage of the DITA (Darwin Information Type Architecture). And there is embedded Help that displays the Help as part of the user interface, usually in a dedicated pane that can be hidden.
The advantage of Help over other forms of product documentation is that it is included as part of the application, and its content can be closely coordinated with user tasks. The disadvantage of Help is that it does not handle long background or overview content very well. See my other column, The Help Landscape: A Mile Wide and Thirty Seconds Deep.
In his role as User Experience Architect for IBM Security, Mike’s professional focus is on designing usable user interfaces that accommodate the user as learner. Previously, as User Assistance Architect at IBM, Mike identified tools, methods, and standards for integrating the content and delivery of user assistance, including documentation, Help, elearning, and training. He was formerly Lead UX Designer for CheckFree Corporation, where he instituted their User Experience Research and Design Center. Mike has a PhD in Instructional Technology from the University of Georgia and a Masters in Technical and Professional Communication from Southern Polytechnic State University. He is a Fellow with the Society for Technical Communication and a Certified Performance Technologist through the International Society for Performance Improvement. Read More