Excerpts from Chapter 5: Advanced Voice User Interface Design
[This] Chapter [covers advanced] voice user interface (VUI) design [topics]. Here, we take a look at what will make [your VUIs] engaging, easy to use, and successful.
Siri and the Amazon Echo are both examples of popular VUIs. The Echo has recently received a lot of praise about its interface. Given that the two systems can do many similar things, why is the Echo often a better user experience? One reason is that the Echo was designed with voice in mind from the beginning—that’s its sole purpose. Siri, by comparison, is just one more way to interact with your iPhone.
Champion Advertisement
Continue Reading…
As Kathryn Whitenton writes: “The Echo, on the other hand, prioritizes voice interaction above all else.” She goes on:
“Siri’s ability to expedite Web searches with voice input for queries is certainly valuable, but the bias toward interpreting user questions as Web searches can actually increase error rates when doing other tasks. The benefit of the Echo’s more focused functionality is even more apparent if you need multiple timers—not an uncommon scenario when cooking. When asked to set a new timer, Alexa easily responds, ‘Second timer set for 40 minutes, starting now,’ while Siri, which only has one timer, balks: ‘Your timer’s already running, at 9 minutes and 42 seconds. Would you like to change it?’
“But for short tasks, failing to hear a command the first time can easily tip the balance, and make the voice system more cumbersome and time consuming than an existing physical alternative, such as glancing at a digital timer or walking across the room to flip a light switch. New technologies must make tasks faster and easier in order to be viable replacements for existing tools. For short tasks, voice detection errors can make this impossible.” [1]
Much of what has been discussed so far relates to the speech recognition piece of VUIs, and not the natural-language understanding (NLU) part. Speech recognition refers to the words that the recognition engine returns; NLU is how you interpret those responses. Today, with the improvements in speech recognition accuracy, the challenges of designing a good VUI lie more in the NLU—the way the input is handled—than in the technology itself.
Let’s begin by looking at the various ways a VUI can respond to input.
Disambiguation
This leads us to the next area of complexity: disambiguation.
Humans are not always clear. Even when we talk to other humans, we often need to ask follow-up questions to ensure that we understand what the other person meant. Imagine you work at a café, and a customer walks up and says, “I’d like a large, please.” You might be pretty sure they’re talking about ordering a coffee, but because you have other items, as well, you need to ask a follow-up question: “Did you want a large coffee, tea, or juice?”
VUIs will of course encounter the same situations.
Not Enough Information
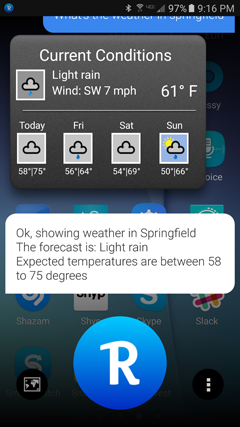
As demonstrated in the preceding example of a customer simply ordering a “large,” people do not always give enough information to complete the task. Take the example of asking for the weather in Springfield. In the United States, there are 34 towns and cities named Springfield. If I am in the United States and I say, “What’s the weather in Springfield?” the system should ask me which state. When thinking about this example, I decided to try a few different virtual assistants and see how they handled it. I was rather surprised to discover that none of them disambiguated. All seven that I tried just chose the city for me, without any follow-up! (All of them did correctly recognize “What’s the weather in Springfield?” because I could see the result displayed on the screen.) I’m in California, but the cities that the virtual assistants selected ranged dramatically, as Table 5-1 clearly shows. One, in fact, never told me the state, but simply said, “Springfield,” so I still have no idea which one it chose (Figure 5-1).
Table 5-1—The range of Springfields selected by seven virtual assistants
Virtual Assistant
Springfield
Hound
Springfield, Oregon
Cortana
Springfield, Illinois
Api.ai Assistant
Springfield, Illinois
Siri
Springfield, Missouri
Google
Springfield, Missouri
Alexa
Central Coast, Australia
Robin
Springfield, ???
Figure 5-1—I’m not even sure which Springfield Robin chose.
Let’s design an example of a better way to handle this case:
USER
What’s the weather in Springfield?
VIRTUAL ASSISTANT
Springfield…in which state?
USER
Illinois, please.
VIRTUAL ASSISTANT
In Springfield, Illinois, it’s currently 75 degrees.
Another example that falls into the not enough information category is missing intent. In the tech support example, if a user says, “I need help with the Internet,” perhaps they mean their Internet connection isn’t working or that they need help setting up WiFi. Rather than dismiss their query entirely because there is no exact match, keep a list of common topics, and follow up by asking for intent:
TECH SUPPORT ASSISTANT
Hi there, I’m Pat, your tech support assistant. How can I help you today?
USER
I need help with the Internet.
TECH SUPPORT ASSISTANT
Internet. Sure, I can help with that. Let me get some more information from you first.
I can help you set up your WiFi, find information online, or fix your Internet connection. Which one do you need help with?
More Than One Piece of Information When Only One Is Expected
Another situation in which disambiguation is needed is when the user gives too much information. This often occurs when the user is asked for one specific item, but, naturally, provides more. For example, a medical app might ask, “What is your main symptom?” It’s possible it’s only programmed to handle one symptom at a time—but people will often say more, such as, “I have a fever and a cough.”
There are several strategies at this point:
Take the first symptom recognized (fever).
Reject the entire response because “fever and a cough” is not one of the available symptoms.
Disambiguate.
The ideal technique is to disambiguate. You don’t need to hide the fact that you need to do one symptom at a time—let the user help:
HEALTH ASSISTANT
What is your main symptom?
USER
I have a fever and a cough.
HEALTH ASSISTANT
Which one of those would you say is bothering you the most right now?
USER
The cough…it’s pretty bad.
HEALTH ASSISTANT
OK, let’s start with the cough. I can also help with the fever symptom later.
In this case, the system has simply asked the user to focus first on the most pressing symptom. This can still be a helpful, useful experience. Two other notes on this design:
If the user said up front they had a fever, don’t ask about it later when asking questions about their cough. The system will lose credibility.
Creators of VUI systems often think that if they just put all the instructions up front, people will say the right thing. You might be tempted to change the initial prompt to “Please tell me your main symptom, but only one.” This is not advisable. First, it makes the dialog less natural. Second, a lot of users will ignore it anyway. You still need to build in a way to respond. Doing user testing—with real users out in the world—will also help you to craft prompts to elicit the best responses.
A different example of this is when users say “both,” as in the following example:
VIRTUAL ASSISTANT
Which one would you like, a map or the phone number?
USER
Both.
VIRTUAL ASSISTANT
OK, I’ll give you a map first and then the phone number.
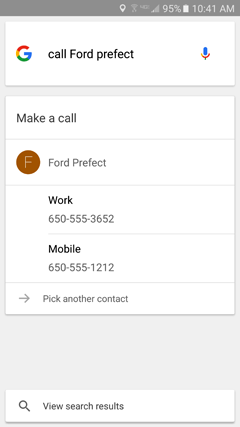
A common example where disambiguation is used is for making phone calls. If I ask Google to call someone in my Contacts list, and there is more than one phone number listed, it shows both and asks me to disambiguate by saying, “Sure. Mobile or work?”
If I say nothing, Google adds additional help by saying, “To keep going, just say which phone number you want to use. For instance, you can say ‘the first one.’” It’s multimodal, of course: I can also tap the one I want (Figure 5-2). Being able to use my voice is important here because I might be driving or otherwise need hands-free interaction.
Figure 5-2—Google disambiguating: which number do you want to call?
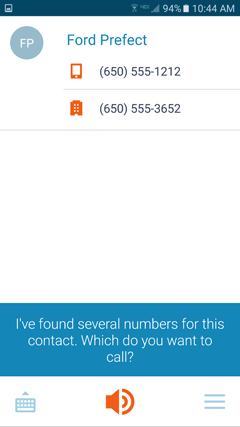
This is a common workflow. Api’s Assistant uses a similar method, as depicted in Figure 5-3.
Figure 5-3—Assistant’s call disambiguation
I have noticed improvements to these systems over time. In the past, when I asked to text a contact, for example, Google asked if I wanted to text the home or mobile number. Recently, it defaults to the mobile number, which makes sense given that it’s impossible to text someone’s home phone.
Handling Negation
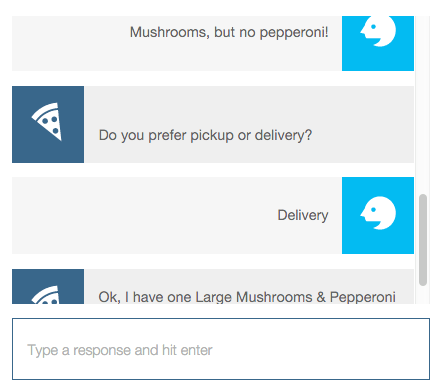
Recently I tried out a pizza chatbot. It asked me for toppings, and I typed “Mushrooms, but no pepperoni!” The confirmation (see Figure 5-4) displayed, “OK, I have one Large Mushrooms & Pepperoni pizza for delivery. Is that correct?”
Figure 5-4—Pizza chatbot ignores the negative
This illustrates the importance of looking out for negative responses, such as not, no, and neither. Imagine how the dialog would sound if upon asking, “How are you feeling today?” the user says “Not very good,” and your VUI—matching on the word good—responds with a cheery “Great to hear!” Your user will probably think your VUI is either sarcastic or stupid, neither of which makes a great impression. Handling these takes more work, but the cost of ignoring them can be high.
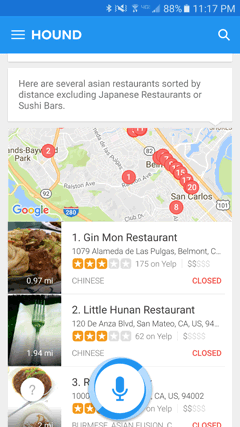
Hound has a good example of handling this well: when I say, “Show me nearby Asian restaurants except for Japanese,” it manages to do just that (Figure 5-5).
Figure 5-5—Hound handling exceptions in a restaurant search
Capturing Intent and Objects
As your VUI becomes more complex, your strategies for handling speech input must become smarter. The previous examples generally have one intent, or action, that the user wants to take. In the disambiguation example, when the user said, “Internet,” the system asked a clarifying question to determine what the user needed help with in terms of their Internet connection.
More advanced systems can determine the intent upon an object on its own. For example, with a virtual assistant such as Siri, there are multiple things you can do with the calendar: view your calendar, add events, and cancel events. In this type of system, simply matching on the keyword calendar will not be good enough. Instead, your VUI’s NLU model must be trained to understand that the following sentences, although all related to the calendar, will ultimately result in different actions:
Show me my calendar.
Add an event to my calendar.
Delete my meeting from my calendar.
Building these types of models—and more complex ones—is beyond the scope of this book. There are third-party tools that you can use to create these more complex models. These tools provide sample sets of examples that allow you to build up a more complex set of ways in which users can interact with your VUI. Some examples of tools include Api.ai—now owned by Google; Nuance Mix, Wit.ai—Facebook; Houndify, Microsoft LUIS, and Amazon Echo.
Dialog Management
To make your VUI as flexible as possible, a concept called dialog management will become important. Dialog management is how the system manages what has already occurred in the conversation and what needs to happen next. This is important because users want to provide information in different ways; someone will give all the information up front, and some will provide it piece by piece. To handle this, the app needs to know what bits of information are needed—these bits are sometimes referred to as slots—and in what order to ask for them.
Here’s an example using the ever-popular pizza-ordering domain. (Did you know the average American eats about 46 slices of pizza each year?) The information slots that need to be acquired to successfully order a pizza include the following:
Number of pizzas
Size(s)
Toppings
Street address
Phone number
Zip code
Your VUI could force the user to go down the exact same path every time to get these, but a better way is to let the user provide the information the way they most want to:
PIZZA APP
Hi there, welcome to Pearl’s Pizza, home of the famous gingerbread pizza crust. What kind of pizza can I get you?
USER
Um, I’d like a large pepperoni, please.
[At this point, we have filled in the number of pizzas—1, and the toppings—pepperoni. Now, we know all that remains is the address and phone number.]
PIZZA APP
That’s one large pepperoni. Great. What’s the delivery address?
USER
Cherry Lane.
PIZZA APP
And the street number?
USER
321.
PIZZA APP
And finally, what’s your zip code?
USER
94019.
Now let’s see how another user might respond to this task:
PIZZA APP
Hi there, welcome to Pearl’s Pizza, home of the famous gingerbread pizza crust. What kind of pizza can I get you?
USER
Uhh…yeah, I wanna order some pizzas.
PIZZA APP
Great, that’s what I’m here for. How many would you like?
USER
Two, please.
PIZZA
And what sizes?
USER
One small, one large.
PIZZA APP
OK, let’s start with the small. What ingredients would you like on that one?
USER
Olives, mushrooms, and sun-dried tomatoes.
PIZZA APP
Olives, mushrooms, sun-dried tomatoes. Sounds delicious. Now, what about the large; what ingredients would you like on that one?
In the second example, the user started out at a much higher level, but the pizza app successfully led them through the necessary questions to get the information. Follow your user’s lead, and be prepared to handle information in a variety of ways.
Sentiment Analysis and Emotion Detection
One way to make your VUI smarter and more empathetic is to use sentiment analysis. Sentiment analysis, as defined by Google, is:
“The process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer’s attitude towards a particular topic, product, etc., is positive, negative, or neutral.”
In the VUI world, this means using natural-language processing to extract information about how the user is feeling. It might sound complicated, but you can begin to do basic sentiment analysis in a fairly straightforward manner. First, you need to define your categories. You can begin simply, for example, with positive and negative. By using lists of positive and negative words, you can compare what the user said, and categorize accordingly.
There are even free word lists already created and available for your use, such as the MPQA negative and positive lists, available from the University of Pittsburgh. Open source tools such as KNIME can perform post-processing on your recognition results to examine what percent of the time your users are saying negative words versus positive words.
Emotion detection is still fairly new. Companies such as Affectiva have already begun using emotion detection techniques that look at a person’s facial features. The company has employed this in market research; for example, while participants watch movie trailers, it tracks their facial features and determines their emotional response to various parts of the trailer.
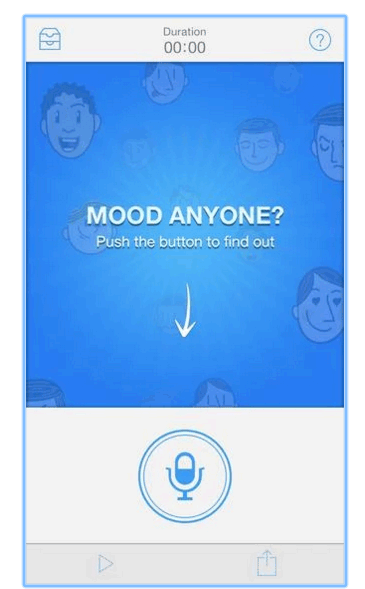
Beyond Verbal detects emotions via a voice stream by analyzing vocal intonations in real time. With its Moodies app, users press a button and talk about their thoughts—after 20 seconds, the app displays their primary emotion, as shown in Figure 5-7.
Figure 5-7—Beyond Verbal’s Moodies app
One of the key principles to keep in mind when using technologies that deal with a user’s emotion is to always err on the side of caution. Getting the user’s emotional state right is great—getting it wrong can have a very high cost. Never come right out and name the user’s emotion; for example, “You’re feeling sad.” Maybe the user is indeed feeling sad, maybe they aren’t; but they might not want to admit it. We’ve all experienced saying to someone, “I can tell you’re upset,” only to have the person vehemently deny it.
Instead, use the sentiment and emotion analysis to steer the conversation. Perhaps someone has expressed negative emotions over multiple days this week when chatting with your VUI; the system could ask more questions, and dig a little deeper into how the person is actually feeling.
Context
One reason many virtual assistants—as well as chatbots—currently struggle with conversational UI is because they lack context. Context means being aware of what’s going on around the conversation, as well as things that have happened in the past.
Remembering details of the conversation can be quite challenging, but one can still take advantage of basic context to make your VUI seem smarter as well as saving users’ time.
For example, you can determine which time zone your user is in and greet them appropriately—“Good morning,” “Good afternoon,” and so on. You can use location; knowing that a user is at home and not at the office when they are searching for a restaurant will alter the search results you present.
If you ask your user every day how they slept, rather than act like the previous day never happened, alter the question with some background. Instead of “How many hours did you sleep last night?” the assistant could say, “I know you’ve been a bit short on sleep this week. How many hours were you able to get last night?”
Even within the same conversation, pay attention to things your user might say that are not responses to the direct question. If the user tells a tech support app, “My Internet hasn’t been working for a week,” don’t follow up with, “How long has your Internet not been working?”
These are jarring reminders to the user that your system is just a dumb computer. Remembering that last week your user got their personal best time when they went for a run is not terribly difficult, computationally speaking. But knowing simple details like that will enable your VUI to engage the user more, to become more trusted, and more personable.
Advanced NLU
A virtual assistant just doing a Web search doesn’t show understanding.—Deborah Dahl, Mobile Voice 2016
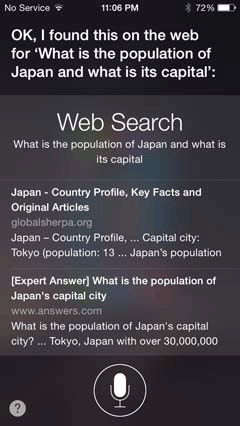
When confronted with a request they cannot answer, many virtual assistants will punt to a regular search command. Look at the difference between Siri and Hound when both are asked the question, “What is the population of Japan, and what is its capital?” Siri can’t handle that question, so it backs off to, “OK, I found this on the Web for “What is the population of Japan and what is its capital?” and shows a list of search results (Figure 5-8). Now, the first search result will actually give you all the information you need, but it does not answer the question directly.
Figure 5-8—Siri goes to Web search when it doesn’t know the answer
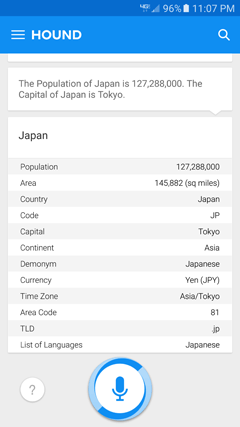
In Hound’s case, it says the answer right up front, and then provides additional information (Figure 5-9).
Figure 5-9—An example of Hound handling a two-part question
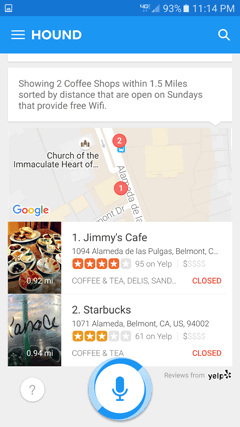
Hound has a knack for responding to multiple queries in one. Take a look at this doozy: “Show me coffee shops that have WiFi, are open on Sundays, and are within walking distance of my house.” Hound can actually handle this quite gracefully (see Figure 5-10).
Figure 5-10—Hound handling a multipart request
This type of query draws a collective gasp when it’s demonstrated before a live audience. It impresses people. But if you break it down, it’s really just a series of simpler commands, concatenated.
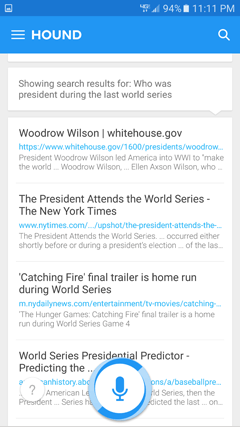
Let’s try something more complex: from an NLU perspective. When I ask Hound, “Who was president during the last World Series?” it backs off to search results. The first one? A page on Woodrow Wilson. This query is only asking for one piece of information—but it requires the underlying system to have a much more complex model of the world (Figure 5-11).
Figure 5-11—Hound goes to Web search if it can’t answer a question
These examples show that VUI is not a solved problem. In all of these cases, the speech recognition was flawless. It recognized my question exactly. But that’s not enough—in addition, the VUI must understand the subtleties of language.
What Hound does is very impressive—but that’s generally not how people talk. If I call up a catalog company to order something, I give the information in chunks. Rather than saying, “I’d like to order a large men’s shirt that is blue and has buttons and is short sleeved and is under $50,” I’m more likely to begin with, “I’d like to order a men’s shirt,” and go from there. Your VUI will be most successful if it can remember what already took place, and keep the system grounded.
It might make for a more impressive investor meeting if you can demonstrate rattling off multiple commands at once, but users don’t always mind if a task takes multiple steps. As long as the questions feel relevant, and the user feels like they’re getting somewhere, they’ll put up with a lot.
Another thing to keep in mind is that your user might give more information than you asked for. For example, you might think you’re asking a simple yes/no question with, “Now, do you know the flight number?” But the user might give you “Yes” as well as “Yeah, it’s 457.”
As designers, we don’t get to create the underlying elements of conversation. (For example, we must follow human conventions.) [5]
As Randy Harris says:
Voice enabling the Web for the sake of voice enabling the Web is pointless, but there are Web sites galore with promise for useful speech interaction. The trick—provided there is a service with a potential customer base—is not to treat the Web site itself as primary, but as the graphic interface to data the customer wants to access. It’s the data, not the site, that is the key. [6]
Conclusion
To make your VUI perform above and beyond a basic exchange of information, take advantage of the concepts outlined in this chapter, such as allowing for more complex input by the user by going beyond simple keyword recognition.
Think carefully about design choices such as using TTS or a recorded voice. Use natural-sounding concatenation strategies to improve comprehension. Spend time outlining whether your VUI should have a wake word or require push-to-talk.
Make your VUI more successful out of the gate by bootstrapping your datasets with information that’s already out there or by doing your own data collection.
Using all of these techniques will make your VUI easier to use, more accurate, and more successful.
Previously, Cathy was VP of User Experience at Sensely, whose virtual-nurse avatar, Molly, helps people engage with their healthcare. An expert in voice user interface design, Cathy is the author of the O’Reilly book Designing Voice User Interfaces. She has worked on everything from NASA helicopter-pilot simulators to a conversational iPad app in which Esquire magazine’s style columnist tells users what they should wear on a first date. During her time at Nuance and Microsoft, Cathy designed VUIs (Voice User Interfaces) for banks, airlines, and Ford SYNC. She holds a BS in Cognitive Science from UCSD and an MS in Computer Science from Indiana University. Read More