The Evolution of an Idea
For three years, from 2003 to 2006, my work focused on eyetracking studies. During that time, my team and I discovered a really important innovation in interaction design. We created user interfaces based on eyetracking that could radically transform people’s everyday use of personal computers. The computer seems magical, because it can understand what you really want to do. Personal computers that have eye-driven user interfaces can predict what you want to do next, because your attention and the focus of your vision shift so quickly—almost before you are aware of it. These computers don’t use AI or smart algorithms. They just provide a way for people to communicate with them directly.
Throughout 2005, I encountered some amazing new technologies that could potentially change our usual way of interacting with computers. One such technology is Jeff Han’s multi-touch sensing system,![]() which lets one or more people interact with a computer by touching a large screen that supports many new modes of interaction. Users can touch, drag, or select any object on the screen. While there’s nothing particularly innovative about such interactions in themselves, this system works really well. Han’s multi-touch sensing system represents the state of the art in tangible user interfaces.
which lets one or more people interact with a computer by touching a large screen that supports many new modes of interaction. Users can touch, drag, or select any object on the screen. While there’s nothing particularly innovative about such interactions in themselves, this system works really well. Han’s multi-touch sensing system represents the state of the art in tangible user interfaces.
Some months ago, Nintendo introduced another fascinating way of interacting with computers: the perfect way to play a game freely, using a virtual lightsaber!![]() While this device is strongly related to gaming, it shows the potential for radically new input devices.
While this device is strongly related to gaming, it shows the potential for radically new input devices.
Early in 2006, I became involved with a new product development team. We considered how we could bring together all of these new input devices and, more importantly, how users could transmit emotions like stress or calmness to machines. In a few months, we discovered that a lot of applicable technologies already existed, but were on the back burner. For example, there is a voice-based mood recognition system that can understand the emotional status of a user. While we could combine current technologies that have evolved independently of one another in several different ways, we decided to design a CRM (Customer Relationship Management) decision-tree that lets a computer choose what to say to a user considering his or her mood.
After this first experience, we became aware that software based on a decision-tree could not be sufficiently powerful to sustain credibility over the long run. On the other hand, by using an artificial intelligence framework and restricting the computer’s knowledge to a specific topic or field, we were able to enhance the ability of our system to give the right answers, depending on a user’s mood.
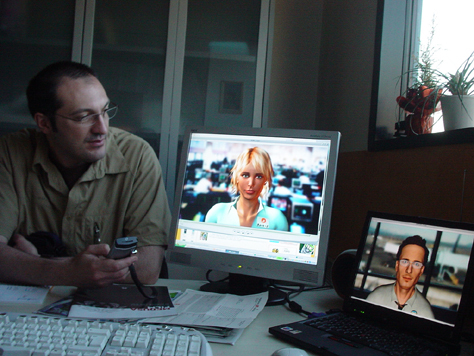
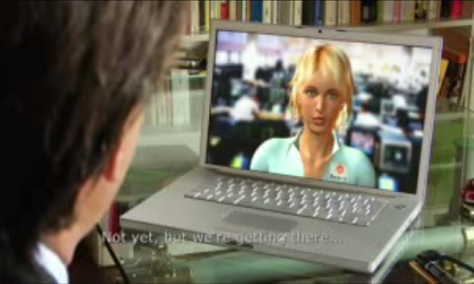
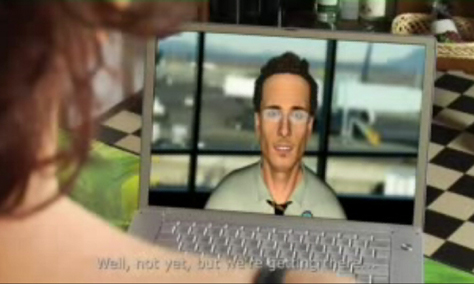
Now, we are working to mash up an application that uses open source APIs (Application Program Interfaces) for general purpose Web sites, but enriches standard XML by adding an emotional layer to the user experience. In this way, we have created a computer system that has the ability to provide information with emotional connotations to users—even if this information comes from an external source. For example, we have created a virtual personal assistant that can more or less emulate the mood of a user. For example, depending on a user’s specific mood, the assistant may seem calm or hurried.
I like to think about this new phase we’re entering as one of technological biodiversity—as opposed to the GUI (Graphic User Interface) homogeneity we have experienced so far.
The Future of Interactivity
Likely, in the future, human/computer interaction will comprise multimodal inputs rather than just keystrokes and mouse clicks. Of course, such a change requires that user interfaces evolve from windowing systems to multifaceted environments in which emotions play a critical role—emotions both as inputs—allowing computers to understand a little bit more about us—and outputs. Such computers should appear intelligent and be much more forgiving of human error than windowing interfaces.
For us, the key to making this future happen was our decision to build anthropomorphous software, using existing technology. Anthropomorphous software has the following capabilities:
- understands unformatted text
- understands human speech, by means of voice recognition technology
- accepts other input from touch screens, eyetracking devices, DTMF (Dual-Tone Multi-Frequency) signals, etcetera
- reads text, using vocal synthesis technology
- writes text and delivers documents that are stored in a knowledge base system
- performs actions like sending email messages, sending SMS (Short Message Service) text messages, and prints receipts
- interacts with users, emulating the personalities, emotional responses, and behavior of human beings
- dialogues with users in a natural way with the end-goal of understanding their needs, by means expert-systems technology