Algorithms drive the stock market, write articles—but not this one—approve loans, and even drive cars. Algorithms are shaping your experience every day. Your Facebook feed, your Spotify playlists, your Amazon recommendations, and more are creating a personalized window into a world that is driven by algorithms. Algorithms and machine learning help Google Maps determine the best route for you. When you ask Siri or Cortana a question, algorithms help shape what you ask and the information you receive as a response.
As experience designers, we rely more on algorithms with every iteration of a Web site or application. As design becomes less about screens and more about augmenting humans with extended capabilities, new ideas, and even, potentially, more emotional awareness, we need algorithms. If we think of experience designers as the creators of the interface between people and technology, it makes sense that we should become more savvy about algorithms.
Champion Advertisement
Continue Reading…
So, what is an experience designer’s role in a future of big data, algorithms, and machine learning? Let’s start by considering what algorithms can and can’t do. Then we’ll look at some implications for design.
The Mystery of the Algorithm
The term algorithm seems a little mysterious. To some extent, this is marketing mystique. A secret algorithm sounds smart and hard to copy. It may seem like a puzzle to solve. Why does one story get prioritized in my Facebook feed over another? How could we reverse engineer Uber’s surge-pricing algorithm? Algorithms may even feel dangerous. After all, an algorithm caused a flash market crash recently.
What are algorithms anyway?
Part of the confusion around the term algorithm is because of its multiplicity. Algorithm seems to stand in for any data-driven technology. People often use the term interchangeably with artificial intelligence. It’s become a convenient way of describing a combination of big data, algorithms, and machine learning. That makes sense because these three things often work together.
Big data is the raw material that we are producing constantly—every time we engage with technology. Each one of us produces nearly 3.5 million bytes of data every day by interacting with Web sites and using our smartphones, tablets, and wearable devices. Not all of that data gets used for every experience, of course, but algorithms can use data of various types from different sources. The data may be yours alone, or it can come from aggregate groups of people.
Algorithms are a set of guidelines on how to perform a task. When you send a text message, do an Internet search, or stream a movie to your computer, you are triggering a nested set of interdependent algorithms. Some algorithms take the form of basic mathematical functions; others build on those functions. Essentially, they’re a set of instructions. Machine-learning apps like HowOld.net, shown in Figure 1, work by training an algorithm with a lot of data.
Figure 1—HowOld.net
Machine learning is how an algorithm evolves over time. Instead of just repeating a set of instructions, machine learning is a system that reinvents itself as it works. Machines actually learn to get things right by repeatedly getting them wrong. If an algorithm messes up how old you look in a picture, you can laugh it off. If it identifies human beings as gorillas, it’s horrifying. And that’s not the only downside.
The Limitations of Algorithms
Even though algorithms open up a lot of possibilities, there are some limitations. As experience designers, we need to be aware of them. If we know the limitations, we can actually design experiences to compensate for them. And we know when it’s better to rely on human intelligence.
Algorithms are not neutral or objective.
Algorithms—like Web sites or apps or organizations or people—have a point of view. Personalization algorithms exist not just to create a better experience, but because organizations have business goals. Humans create algorithms, so their point of view gets embedded in the system. Sometimes that point of view is obvious—for example, an ad that appears based on some of your personal data. Sometimes it’s less obvious, until we encounter a flaw.
Algorithms rely on a data ownership—or the lack of it.
Most of us have only the vaguest sense of what data we are leaving behind and who is using it. The right to have control over your data is a big part of the conversation around algorithms. Hopefully, we will move toward more individual control. For now, there are big differences in privacy among the sites, organizations, and countries that shape algorithms.
Algorithms don’t understand you as a complex individual.
Whether you call it the uncanny valley of personalization or your data double, you can sometimes be confronted with a frighteningly accurate picture of yourself. But, most of the time, it’s a little off base. Different sites serve different interests, so they capture different preferences. (Amazon is quite different from OkCupid, for instance.) Algorithms generalize and simplify, filtering out things they consider to be irrelevant. In many cases, algorithms use other people’s data to fill in missing bits and pieces. The end result is that algorithms don’t reflect the ever-changing, complicated person you are. But on aboutthedata.com, shown in Figure 2, the data vendor Acxiom lets you view and, if you want to, adjust their data about you.
Figure 2—Acxiom’s aboutthedata.com
Algorithms are opaque.
As much as we rely on algorithms, it’s not always clear how they work or why they work the way they do. Machine-learning algorithms can become so complex that the people who write them don’t fully understand how they work. In other words, personalization is not transparent. As much as people try to understand and change personalization algorithms, that is not easy to accomplish.
Algorithms may end up automating our lives excessively.
Algorithms increasingly take over tasks that we once performed on our own—for example, planning our route on a drive or walk. This may leave us with only narrowly circumscribed routines. Algorithms automate the experience of discovery, but strip away some of the pleasure of uncertainty. The better they know our tastes, the less time we spend imagining new possibilities. Algorithms automate our experience of new people and new ideas, so we may feel that we are in an echo chamber. As designers, we have to think about balance.
Despite all of these complications, our designs rely on algorithms more and more. Why? Because algorithms promise to simplify our experience of technology—maybe even to the point of having no user interface at all. Personalized experiences, conversational apps, and chat bots all have algorithms at their foundation. As experience designers try to resolve the algorithm and the user interface, it’s important to understand the limitations of algorithms. How we design an experience can counteract some of the negative effects of algorithms.
So, how do we get started, without becoming data scientists or algorithm designers ourselves?
Designing with Algorithms
Data tells us about people and organizations. Algorithms create guidelines. Machine learning shapes the experience. While all of this sounds familiar and is relevant to the work we do, we still wonder: Should designers write algorithms? Should designers understand how machines learn? Are we input or output? The distinctions are collapsing a bit more every day. Here are three ways you can get started designing with algorithms.
1. Start with the end.
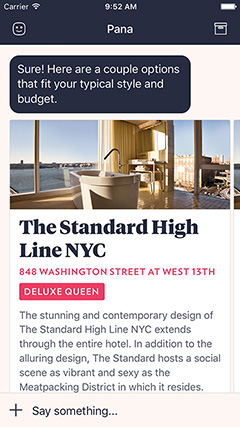
Whether you decide to turn your attention to output, focus on input, or both, designing with algorithms begins at the end. When designers collaborate on designing algorithm-driven experiences, we can think through what should be human facing. Giles Colbourne describes a process of mapping outputs as a conversation to help plan the data to use as inputs. Designers can help determine how data can enrich the experience—as well as when it doesn’t. Think of a conversational travel app such as Pana, which needs to decide when to remember and use your travel preferences and when to ask you about them.
Figure 3—Pana balances human and artificial intelligence in a conversational interface
2. Play a role in data selection.
Once we encourage a dialogue between a data scientist and an experience designer about what’s possible and how to present it, we can also play a role in selecting the data with which to train the algorithm and to use on an ongoing basis. It may even mean a different approach to designing the algorithm itself. For example, when working on an ecommerce site like Zappos, a designer might recommend using more historical purchase data and less data showing a particular profile’s similarities to other customers.
3. Bridge the disconnect.
Algorithms can spin off their own stories. We all encounter this when we feel a disconnect between ourselves and the version of ourselves that gets reflected back to us when we view a social-media profile or are served an ad. Designing for algorithms means taking a new approach to defining the person on the receiving end. That person is a collection of data points, a real person we interviewed, a close match that a personalization algorithm generated, and an idealized muse. We need to think about all of these instances of a person when we design with algorithms. Lately, I’ve been working with teams to create a persona for each instance and role play the interactions.
Guidelines for Designing with Algorithms
Designers have an important role to play in figuring out how an algorithm translates to an experience. I think we also have a role as user advocates, making sure that we continue to design for humanity in the algorithmic age. Here are a few guidelines I’ve been using.
Follow the Principle of Minimum Viable Data
The impulse of most organizations is to collect as much data as possible, just in case. Since individuals have little control over their data or how organizations use it, encouraging minimalism makes sense. With the coming wave of emotion-sensing apps and devices, a minimal approach will become even more important. More is not necessarily better for algorithms or user interfaces. Maciej Ceglowski’s talk on data and privacy really brings this issue to life.
Reveal the Algorithm and Its Effects
Of course, people don’t want to see code. They don’t even want to adjust settings. From my research practice, I can see that people prefer to game an algorithm by launching a private window here, clicking something there, following, and unfollowing. They do this because they don’t really understand what data the algorithm uses, how the algorithm works, or how the user interface evolves as a result. As experience designers, we can take on this problem and make algorithms’ effects more apparent. Lauren McCarthy’s Facebook Mood Manipulator, which uses the same algorithm that Facebook used in their controversial emotional contagion research, is an experiment on how we could get more control over what we see.
Allow People to Participate in Creating Their Algorithms
Once we’ve made algorithms more transparent, the next thing we should do is let people participate in their data creation. You can choose your own appearance and identity. Crystal is an example of an app that generates a personality profile by analyzing a person’s social-media profiles and other publicly available data. It also invites users to answer questions that let them shape their profile. In the future, I’d like to see ways for users to challenge algorithms that serve someone else’s interests, choose a level of trust using different personal preferences, and turn off the algorithms designed into an experience.
Conclusion
Today, algorithms shape what we experience online. Next, they’ll modify our physical world—our homes, workplaces, cars, and cities. The new material of invisible, personalized, conversational design is algorithms. As experience designers, we can take an active role in bridging algorithms and the user interface to bring greater humanity to the experiences people have with technology.
I started reading CLRS 3rd edition, which is my textbook on algorithms. It said in the introduction, while discussing the applications of algorithms, that the design of any GUI relies on algorithms. I was intrigued so I searched via Google and reached this page. I must say that I liked the UI and content of this article.
I hope to learn more about algorithms and their applications.
Pamela is founder of Change Sciences, a UX research and strategy firm for Fortune 500s, startups, and other smart companies. She’s got credentials—an MS in Information Science from the University of Michigan—and has worked with lots of big brands, including Ally, Corcoran, Digitas, eMusic, NBC Universal, McGarry Bowen, PNC, Prudential, VEVO, Verizon, and Wiley. Plus, Pamela has UX street cred: She’s logged thousands of hours in the field, trying to better understand how people use technology, and has run hundreds of UX studies on almost every type of site or application you could imagine. When she’s not talking to strangers about their experiences online or sifting through messy data looking for patterns, she’s busy writing and speaking about how to create better user experiences using data of all shapes and sizes. Read More